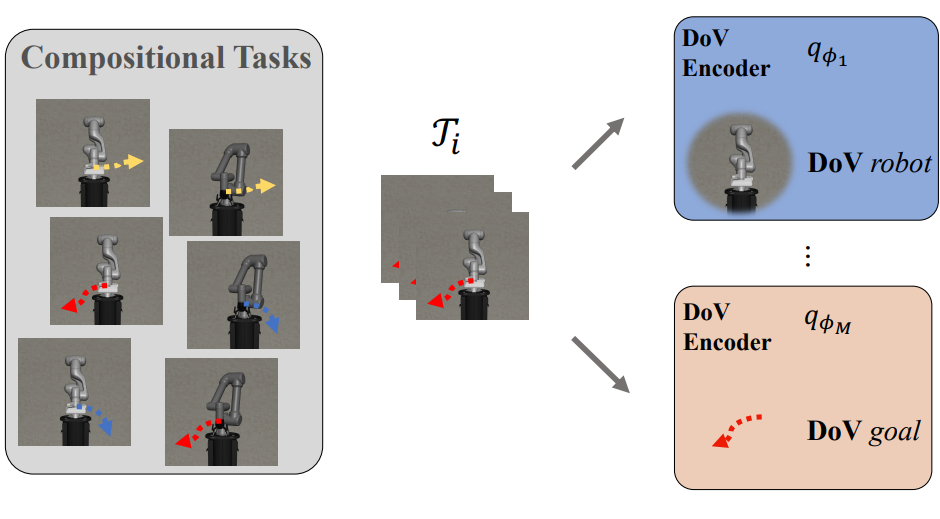
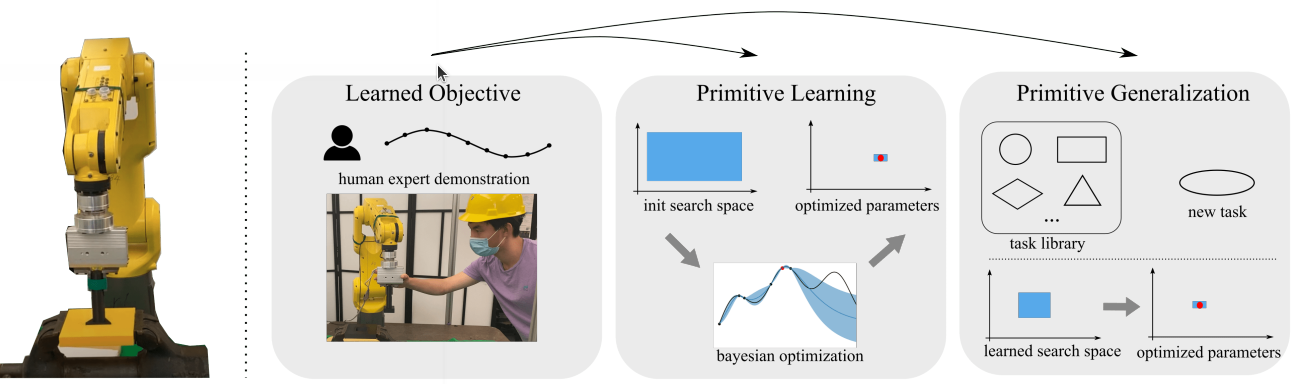
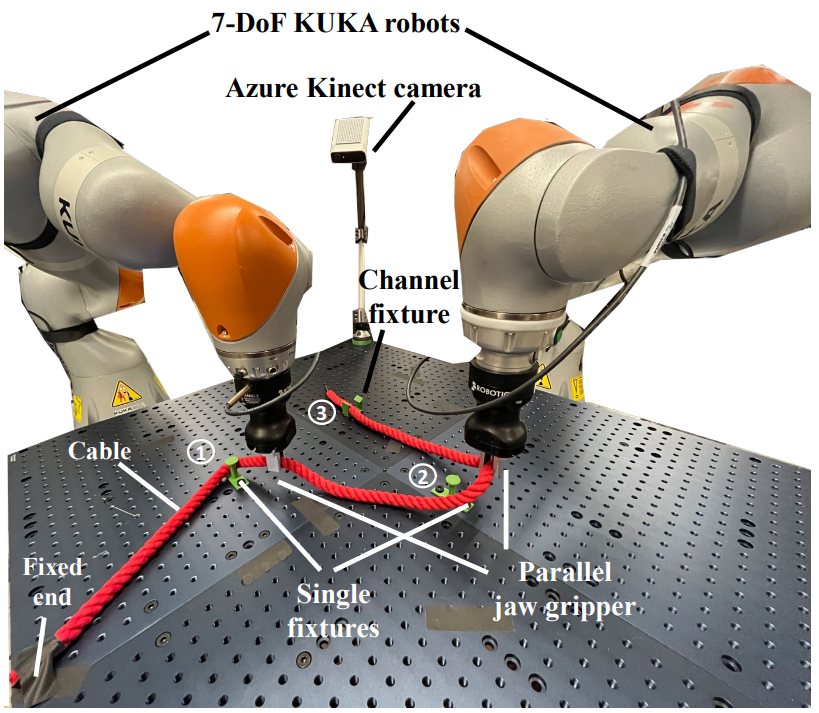
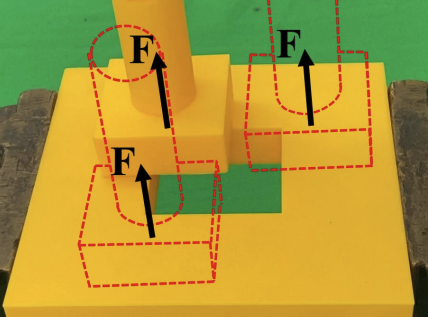
I am a postdoctoral researcher at Stanford University working with Prof. Shuran Song. Previously, I worked at Meta Fundamental AI Research (FAIR). My research centers on robot learning for dexterous and contact-rich manipulation.
I received my Ph.D. from UC Berkeley in December 2023 under the supervision of Prof. Masayoshi Tomizuka.
News
- 07/2026: Paper: Multisensory Continual Learning: Adapting Pretrained Visuomotor Policies to Force is now available on arXiv.
- 06/2026: Paper: SPIDER: Scalable Physics-Informed DExterous Retargeting accepted by IROS 2026.
- 04/2026: Paper: OSMO: Open-Source Tactile Glove for Human-to-Robot Skill Transfer accepted by IEEE Robotics and Automation Letters (RA-L).
- 01/2026: Paper: Dexterity from Smart Lenses: Multi-Fingered Robot Manipulation with In-the-Wild Human Demonstrations accepted by ICRA 2026.
- 01/2026: Paper: DexCtrl: Sim-to-Real Dexterity with Adaptive Controller Learning accepted by ICRA 2026.
- 06/2025: Paper: Geometric Retargeting: A Principled, Ultrafast Neural Hand Retargeting Algorithm accepted by IROS 2025.
- 04/2025: Paper: DexterityGen: Foundation Controller for Unprecedented Dexterity accepted by Robotics: Science and Systems (RSS) 2025.
- 07/2024: Paper: Generalizable whole-body global manipulation of deformable linear objects by dual-arm robot in 3-D constrained environments accepted by International Journal of Robotics Research (IJRR).
show more
- 06/2024: Paper: In-Hand Following of Deformable Linear Objects Using Dexterous Fingers with Tactile Sensing accepted by IROS 2024.
- 01/2024: Paper: Distributed Multi-agent Interaction Generation with Imagined Potential Games accepted by American Control Conference (ACC) 2024.
- 12/2023: I defended my Ph.D. dissertation. Here is my thesis .
- 12/2023: Paper: Robot manipulation task learning by leveraging se (3) group invariance and equivariance accepted by IEEE Robotics and Automation Letters (RA-L).
- 09/2023: Paper: Efficient Sim-to-real Transfer of Contact-Rich Manipulation Skills with Online Admittance Residual Learning (website ) accepted by CoRL 2023.
- 06/2023: Paper: A coarse-to-fine framework for dual-arm manipulation of deformable linear objects with whole-body obstacle avoidance (video ) won the Best Paper Award at the ICRA 2023 Workshop on Representing and Manipulating Deformable Objects .
- 01/2023: Paper: A coarse-to-fine framework for dual-arm manipulation of deformable linear objects with whole-body obstacle avoidance accepted by ICRA 2023.
- 01/2023: Paper: Zero-Shot Policy Transfer with Disentangled Task Representation of Meta-Reinforcement Learning accepted by ICRA 2023.
- 05/2022: Paper: Safe Online Gain Optimization for Cartesian Space Variable Impedance Control accepted by CASE 2022.
- 02/2022 Paper: Offline-Online Learning of Deformation Model for Cable Manipulation With Graph Neural Networks accepted by IEEE Robotics and Automation Letters (RA-L).
- 02/2022: Paper: Robotic cable routing with spatial representation accepted by IEEE Robotics and Automation Letters (RA-L).
- 01/2022: Paper: Learning Insertion Primitives with Discrete-Continuous Hybrid Action Space for Robotic Assembly Tasks accepted by ICRA 2022
- 01/2022: Paper: BPOMP: A Bilevel Path Optimization Formulation for Motion Planning accepted by ACC 2022
- 06/2021: Paper: Trajectory Splitting: A Distributed Formulation for Collision Avoiding Trajectory Optimization accepted by IROS 2021.
- 06/2021: Paper: Online Learning of Unknown Dynamics for Model-Based Controllers in Legged Locomotion accepted by IEEE Robotics and Automation Letters (RA-L).
- 01/2021: Paper: Contact Pose Identification for Peg-in-hole Assembly under Uncertainties accepted by ACC 2020.
- 06/2019: Paper: Robust Deformation Model Approximation for Robotic Cable Manipulation accepted by IROS 2019.
- 07/2018: Paper: A Framework for Manipulating Deformable Linear Objects by Coherent Point Drift accepted by IEEE Robotics and Automation Letters (RA-L).
Research
![]() SPIDER: Scalable Physics-Informed DExterous Retargeting
SPIDER: Scalable Physics-Informed DExterous Retargeting
Chaoyi Pan, Changhao Wang, Haozhi Qi, Julen Urain, Zixi Liu, Homanga Bharadhwa, Akash Sharma, Tingfan Wu, Guanya Shi, Jitendra Malik, Francois Hogan
IROS 2026